
Bằng cách nào mà Google có thể hiểu được nội dung trên Website? Hãy cùng theo dõi bài viết dưới đây.
Crawling trong SEO là một trong những khái niệm cơ bản nhất khi làm SEO. Vậy Crawling là gì? Bài viết dưới đây sẽ trả lời chi tiết.
Crawling là gì?
Crawling (thu thập thông tin) là quá trình khám phá trong đó các công cụ tìm kiếm (Google, Bing, Yahoo,…) gửi ra một nhóm Googlebot. Loại này còn được gọi là trình thu thập thông tin để tìm nội dung mới và cập nhật.
Nội dung có thể khác nhau, có thể là trang web, video, hình ảnh, PDF,… nhưng bất kể là định dạng nào, nội dung hầu hết được phát hiện bởi các liên kết.
Googlebot bắt đầu tìm nạp một vài trang Web. Sau đó, theo các liên kết trên các trang Web đó để tìm các URL mới. Bằng cách này, các công cụ thu thập thông tin có thể tìm thấy nội dung mới và thêm nó vào chỉ mục (Index) của họ có tên là Caffeine. Đây được biết đến là một cơ sở dữ liệu lớn (Big Data) về các URL được phát hiện nhờ vào các liên kết và được tìm kiếm bởi người dùng.
Cách tối ưu quá trình Crawling trang Web
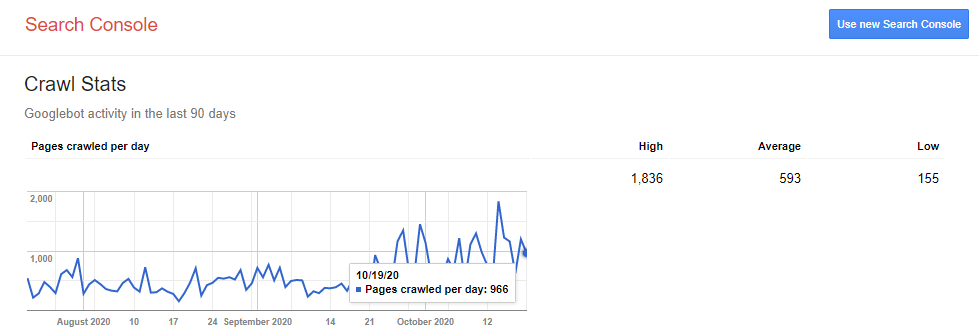
Để tối ưu quá trình Crawling, trước hết cần phải kiểm tra đồ thị Crawling của Google ra sao.
Nhấn vào dòng “Please select a property” để xem chỉ số Crawling.

Từ đây, có thể nhận định được tần suất Crawling của Website của bạn. Qua đó, giúp đưa ra những giải pháp phù hợp để cải thiện.
Cụ thể, có thể liệt kê một số phương pháp giúp tăng tần suất Crawling các trang nội dung trong 1 Website:
- Cập nhật nội dung mới thường xuyên.
- Tối ưu tốc độ tải trang (Page Loading Speed).
- Thêm file Sitemap.xml.
- Cải thiện Server Response Time dưới 200ms, theo Google.
- Xóa bỏ những nội dung trùng lặp trong và ngoài Website.
- Đánh dấu “noindex” những trang không cần thiết trong file Robots.txt.
- Tối ưu hình ảnh, Infographic, Videos.
- Tối ưu Internal Links Structure, vốn là điểm quan trọng trong chiến lược Inbound Marketing, sử dụng những Backlink chất lượng đổ về.
Cách chặn Google Crawling những dữ liệu không quan trọng trên Website
Những trang này có thể bao gồm những :
- URL cũ nội dung mỏng (Thin Content).
- URL trùng lặp (chẳng hạn như tham số sắp xếp và tính năng Filter cho thương mại điện tử).
- Trang mã quảng cáo đặc biệt.
- Trang dàn dựng hoặc Demo.
Dưới đây là một số cách giúp bạn ngăn Google Crawling dữ liệu không quan trọng Website của bạn.
Sử dụng Robots.txt
Để hướng Googlebot ra khỏi các trang và phần nhất định trên trang web của bạn, hãy sử dụng Robots.txt.
Robots.txt là gì?
Các tệp Robots.txt được đặt trong thư mục gốc của các trang web. Tệp này giúp đề xuất công cụ tìm kiếm trang web của bạn nên và không nên thu thập dữ liệu.
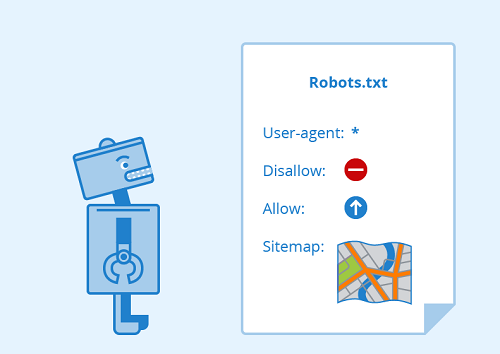
Cách Googlebot xử lý thông tin tệp Robots.txt
- Nếu Googlebot không thể tìm thấy tệp Robots.txt cho một trang web, nó sẽ tiến hành thu thập tất cả dữ liệu trang web.
- Nếu Googlebot tìm thấy tệp Robots.txt cho một trang web, nó thường sẽ tuân theo các chỉ thị và tiến hành thu thập dữ liệu trang web.
- Nếu Googlebot gặp lỗi trong khi cố gắng truy cập tệp Robots.txt, nó sẽ không thu thập dữ liệu trang web.
Tối ưu hóa cho ngân sách thu thập
Ngân sách thu thập (Crawl Budget) là số lượng URL trung bình mà Googlebot sẽ thu thập dữ liệu trên trang web của bạn trước khi rời khỏi.
Vì vậy, để tối ưu hóa quá trình Crawling, hãy đảm bảo rằng:
- Googlebot không quét các trang không quan trọng.
- Chặn trình thu thập thông tin mà bạn chắc chắn không quan trọng.
- Không chặn quyền truy cập của trình thu thập thông tin vào các trang bạn đã thêm các chỉ thị khác như thẻ “Canonical” hoặc “Noindex”.
Cần lưu ý rằng, nếu Googlebot bị chặn từ một trang, nó sẽ không thể xem hướng dẫn trên trang liên kết khác.
Cách để Google Crawling tất cả nội dung quan trọng
Đôi khi, một công cụ tìm kiếm sẽ có thể tìm thấy các phần của trang web của bạn bằng cách thu thập thông tin. Nhưng các trang khác có thể bị che khuất vì lý do này hay lý do khác. Điều quan trọng là đảm bảo rằng các công cụ tìm kiếm có thể khám phá tất cả nội dung bạn muốn Index.
Có thể kể đến một số cách sau:
Bạn có đang dựa vào các hình thức tìm kiếm?
Googlebot sẽ gặp khó khăn khi quét dữ liệu vì các hình thức tìm kiếm. Việc cài đặt Search Box trên trang Web có thể ngăn việc Googlebot thu thập dữ liệu trên trang Web. Vì vậy hãy cân nhắc kỹ lưỡng trọng việc cài đặt Search Box trong Website.
Hidden Text truyền tải nội dung qua phi văn bản
Không nên sử dụng các hình thức đa phương tiện để hiển thị văn bản mà bạn muốn được lập chỉ mục. Bởi lẽ, không có gì có thể đảm bảo họ sẽ có thể đọc và hiểu nó. Thế nên, tốt nhất là thêm văn bản trong phần đánh dấu thẻ <HTML> của trang Web.
Công cụ tìm kiếm có thể theo dõi điều hướng trang web của bạn hay không?
Googlebot khám phá trang Web thông qua các hệ thống Backlink từ các trang Web khác trỏ về hoặc Internal Link của các trang trên tổng thể Website.
Các lỗi điều hướng Link phổ biến
Đây là lý do tại sao trang web của bạn cần có điều hướng rõ ràng và cấu trúc thư mục URL hữu ích:
- Không đồng nhất điều hướng trên giao diện Mobile và Desktop.
- Bất kỳ loại điều hướng nào trong đó các mục menu không có trong thẻ HTML, chẳng hạn như điều hướng hỗ trợ JavaScript. Google đã thu thập thông tin tốt hơn và hiểu Javascript, nhưng đây chưa phải là quy trình hoàn hảo. Cách chắc chắn hơn để đảm bảo một thông tin được tìm thấy, hiểu và lập chỉ mục bởi Google là bằng cách đưa nó vào HTML.
- Cá nhân hóa cho một loại khách truy cập cụ thể so với những người truy cập khác. Việc này chính là đang che giấu trình thu thập công cụ tìm kiếm.
- Không liên kết đến một trang chính trên Website.
Trang Web không có cấu trúc thông tin rõ ràng
Cấu trúc thông tin là điều hành và dán nhãn nội dung trên một trang web để cải thiện hiệu quả và khả năng tìm kiếm cho người dùng. Thế nên, kiến trúc thông tin cần phải trực quan, giúp người dùng không mất nhiều thời gian để tìm kiếm một cái gì đó.
Không sử dụng file Sitemap.xml
Sitemap giống như một danh sách các URL của Website mà trình thu thập thông tin có thể sử dụng để khám phá và lập chỉ mục nội dung của bạn.
Nguồn tham khảo: Crawling là gì?